Algorithmic Methods of Data Mining (Sc.M. in Data Science), 2024
Algorithmic Methods of Data Mining (Sc.M. in Data Science)
Academic year 2024–2025
"The success of companies like Google, Facebook, Amazon, and Netflix, not to mention Wall Street firms and industries from manufacturing and retail to healthcare, is increasingly driven by better tools for extracting meaning from very large quantities of data. 'Data Scientist' is now the hottest job title in Silicon Valley." – Tim O'Reilly
- Data Scientist: The Sexiest Job of the 21st Century
- Find true love with data mining
The course will develop the basic algorithmic techniques for data analysis and mining, with emphasis on massive data sets such as large network data. It will cover the main theoretical and practical aspects behind data mining.
The goal of the course is twofold. First, it will present the main theory behind the analysis of data. Second, it will be hands-on and at the end students will become familiar with various state-of-the-art tools and techniques for analyzing data.
We will cover some very basic topics necessary for handling large data, such as hashing, sorting, graphs, data structures, and databases. We will then move to more advanced data mining topics: text mining, clustering, classification, mining of frequent itemsets, graph mining, visualization.
The theoretical part will be complemented by a laboratory where students will learn how to use tools for analyzing and mining large data. We will base it on Amazon's AWS. After finishing the course, the students will have a large part of the knowledge required to pursue (independently) for an Amazon AWS Certification.
Announcements
The deadline for homework 4 has been extended to December 29.
Homework 5 is out. It is due on December 22.
The deadline for homework 4 has been extended to December 8.
Homework 4 is out. It is due on December 1.
Homework 3 is out. It is due on November 17.
The deadline for homework 2 has been extended to November 3.
Homework 2 is out. It is due on October 27.
Only for this week we will have class on Friday October 4th, at 2pm in Room 14 of the "Tumminelli" building (Building CU007)".
There will be no class on October 2. The class of October 2 will be moved either to October 3 or October 4. Details will follow.
Homework 1 is already out. It is due on October 13. For the part on AWS, you need to wait for the first lab, on October 1.
The first day of the ADM classes is on September 30, 2024. Instead, the week September, 23–27 you will have the Python pre-course.
You need to register to the class mailing list to be able to do homeworks, enter in groups, and so on. Email Aris to do it.
You need to register to:
- the class mailing list to be able to do homeworks, be part of groups, receive announcements, etc.: Send email to Aris.
- Amazon Web Services (AWS): Federico will open an account for you and provide you with details.
- Slack: Send email to Daniel.
Instructors
Aris Anagnostopoulos, Sapienza University of Rome.
Federico Siciliano, Sapienza University of Rome.
Teaching Assistants (TA)
The best way to ask any questions is through slack. If you are registered in the course mailing list and have not received an invitation from Daniel, email Daniel.
Loris Cino (This email address is being protected from spambots. You need JavaScript enabled to view it. ), Ph.D. candidate in Data Science, Sapienza University of Rome (LinkedIn).
Daniel Jiménez (This email address is being protected from spambots. You need JavaScript enabled to view it. ), Ph.D. candidate in Data Science, Sapienza University of Rome (LinkedIn).
Mehrdad Hassanzadeh (This email address is being protected from spambots. You need JavaScript enabled to view it. ), Data Science student, Sapienza University of Rome (LinkedIn).
Edo Fejzic (This email address is being protected from spambots. You need JavaScript enabled to view it. ), Data Science student, Sapienza University of Rome (LinkedIn).
When and where:
Monday 14.00–16.00, Via di Castro Laurenziano 7a (Building RM018), Room 2.
Thursday 12.00–14.00, Main campus, Physics building "Enrico Fermi" (Building CU033), Room 7.
Lab: Tuesday 15.00–19.00, Via Tiburtina 205, Room 17.
Online lectures and nonattending students
There will not be lectures online, only in class. Attending the classes and the lab is, of course, highly recommended. In addition, participation (through making and answering questions) can increase your final grade.
We know that there are students who cannot be in Rome (workers, visa problems, etc.). We mainly use the blackboard during class and online attendance or registration would created overhead for the in-class students, sorry. Make sure that you follow the reading material provided during the semester in this web page, and that you participate (even remotely) in the homework groups.
Office hours
You can use the office hours for any question regarding the class material, past or current homeworks, general questions on data mining, the meaning of life, pretty much anything. Send an email to the TAs and, if needed, to the instructors for arrangement.
Textbook and references
We will use a variety of textbooks. Whenever we can, we will try to find books that are available online. As the course progresses, we will indicate what you should read. The main books that we will use are the:
- (A) C. Aggarwal, "Data Mining: The Textbook," Springer (must be downloaded from Sapienza)
- (ZAL) R. Zafarani, M. A. Abbasi, and H. Liu, "Social Media Mining: An Introduction," Cambridge University Press
- (LRU) J. Leskovec, A. Rajaraman, and J. Ullman, "Mining of Massive Datasets," Cambridge University Press
- (MRS) C. D. Manning, P. Raghavan and H. Schütze, "Introduction to Information Retrieval," Cambridge University Press
- (J) J. Janssens, "Data Science at the Command Line", O'Reilly
In addition, we will cover material from various other sources, which we will post online as the course proceeds.
If you are interested in the topic of algorithms, we recommend the following books:
- T. Cormen, C. Leiserson, R. Rivest, and S. Stein, "Introduction to Algorithms" (4th ed): This is a classic book, very detailed, sometimes too verbose
- S. Dasgupta, C. Papadimitriou, and U. Vazirani, "Algorithms": Very succinct but well written, probably the first book to check out. If you cannot follow it, try one of the other books first
- T. Roughgarden, "Algorithms Illuminated": Another introductory text. It is a more recent book. Tim writes very well.
- J. Kleinberg, and E. Tardos, "Algorithm Design": This is a more advanced book, probably not recommended if it is your first contact with algorithms, but will increase your knowledge a lot if you already know the basic concepts.
Python resources
The main programming language that we will use in the course is Python 3.
To learn the language you can find a lot of material online. You can start from Python's documentation site: https://www.python.org/doc/.
If you would like to buy some books, you can check the
- "Learning Python, 5th edition," by Mark Lutz. It is a bit verbose, but it presents well the features of the language.
- "Python Pocket Reference, 5th edition," by Mark Lutz. It is usefull as a quick reference if you know more or less the language and you are searching for some information.
We will use several libraries in the class. For Windows users the Anaconda distribution has packaged all of them together and you can download it for free. For MAC/Linux users, all packages can be installed using the pip3 tool.
We will also use Python (Jupyter) notebooks. You can find instructions for the installation at the Jupyter web site.
If you have problems with Python installation you can obtain an ubuntu virtual machine with Python preinstalled. Contact the instructor for more information.
Examination format
The standard way to pass the course is to do a set of five homeworks (one individual, four in randomly created groups), which you do during the semester and a final oral exam. Organizational details will be given in class. You also have the option to do a written exam, which we do not recommend (we find that the topic of the class are hard to learn just by studying for an exam). In the previous years, almost everyone chose the first option.
Syllabus
Chapters for which no book is mentioned refer to the "Mining of Massive Datasets" (see below). For the other textbooks, we refer to with the author initials: A, ZAL, MRS.
| Date | Topic | Reading |
| September 30 | Introduction to data science, Introduction to algorithmic data mining | Introduction to Sapienza's Data Science, Introduction to data mining |
| October 1 | Lab 1: Introduction to AWS, S3, EC2 | Slides 1, Slides 2 |
| October 4 | Types of data, introducton to the analysis of algorithms | Notes, chapters 5.0–5.1 |
| October 8 | Lab 2: Introduction to Data Cleaning with Pandas and Visualization with Matplotlib | Slides, Notebook |
| October 10 | Introduction to the analysis of algorithms (cont.) | Notes, chapters 5.2–5.5 |
| October 14 | Introduction to the analysis of algorithms (cont.) | |
| October 15 | Complexity classes and NP-completeness | Notes, chapter 6 |
| October 17 | Introduction to distance measures | (LRU) Chapter 3.5 |
| October 21 | Dynamic programming for edit distance | Notes, chapter 8 |
| October 24 | Basic data representation in Python | Notes, chapter 1–4 |
| October 28 | Cosine similarity, reprocessing for text mining | (MRS) Chapters 2.0–2.2, 6.3.1–6.3.2 |
| October 29 | tf-idf, inverted indexes | (MRS) Chapters 6.2, 1.0–1.4, 6.3.3 |
| November 4 | Sorting | Book chapters on mergesort and quicksort from the book "Introduction to Algorithms" by Cormern, Leiserson, Rivest, and Stein. |
| November 5 | Lab 4: HTML, BeautifulSoup | Slides, Notebook, Simple Exercises |
| November 7 | Data structures, heaps, heapsort | Notes, chapters 7.0, 7.1.0, 7.1.4, Wikipedia page on data structures Wikipedia page on linked lists, book chapter on heaps and heapsort from the book "Introduction to Algorithms" by Cormern, Leiserson, Rivest, and Stein. |
| November 11 | Hashing | Book chapter on hashing from the book "Algorithms" by Dasgupta, Papadimitriou, and Vazirani |
| November 12 | Lab 5: NLTK, Regex, Indexing, Retrieval | Notebook |
| November 14 | MapReduce | Most of the things we talked about can be found on this quick introduction |
| November 18 | Hierarchical clustering, the k-means problem | Chapters 7.0–7.2, Slides |
| November 19 | Lab 6: MapReduce, PySpark | Notebook |
| November 21 | The k-means algorithm, discussion about initialization | Chapters 7.3.0–7.3.2, Slides |
| November 25 | k-means++, choosing k | Chapter 7.3.3, Slides |
| November 26 | Lab 7: Clustering | Notebook |
| November 28 | Principal component analysis, part 1 | Notes |
| December 2 | Principal component analysis, part 2 | Notes |
| December 3 | Queues, stacks, introduction to graphs, BFS, DFS | Notes, Section 7, Notes on graphs, book chapter on graph representaton from the book "Introduction to Algorithms" by Cormern, Leiserson, Rivest, and Stein Book chapter on BFS and DFS from the book "Algorithms Illuminated" by Roughgarden, |
| December 5 | Shortest paths, Dijkstra's algorithm, MST | Book chapter on Dijkstra's algorithm from the book "Algorithms" by Dasgupta, Papadimitriou, and Vazirani, book chapter on Dijkstra's algorithm from the book "Introduction to Algorithms" by Cormern, Leiserson, Rivest, and Stein book chapter on MST from the book "Algorithms Illuminated" by Roughgarden, book chapter on MST from the book "Introduction to Algorithms" by Cormern, Leiserson, Rivest, and Stein |
| December 9 | Centrality measures | Notes on graphs, Section 3 Chapter 5.1.0–5.1.2, 5.1.4, 5.1.5 |
| December 10 | Lab 8: Graph | Notebook |
| December 12 | PageRank (cont.) | |
| December 17 | Minimum cuts and the contraction algorithm | Book chapter on minimum cut from the book "Probability and Computation" by Mitzenmacher and Upfal |
Homeworks
- Homework 1 (due on 13/10, 23.59)
- Homework 2 (due on
27/103/11, 23.59) - Homework 3 (due on 17/11, 23.59)
- Homework 4 (due on
18/12, 23.59) - Homework 5 (due on
2229/12, 23.59)
Collaboration policy (read carefully!): You can discuss with other students of the course about the projects. However, you must understand well your solutions and the final writeup must be yours and written in isolation. In addition, even though you may discuss about how you could implement an algorithm, what type of libraries to use, and so on, the final code must be yours. You may also consult the internet for information, as long as it does not reveal the solution. If a question asks you to design and implement an algorithm for a problem, it's fine if you find information about how to resolve a problem with character encoding, for example, but it is not fine if you search for the code or the algorithm for the problem you are being asked. For the projects, you can talk with other students of the course about questions on the programming language, libraries, some API issue, and so on, but both the solutions and the programming must be yours. If we find out that you have violated the policy and you have copied in any way you will automatically fail. If you have any doubts about whether something is allowed or not, ask the instructor.
The same applies for generative AI tools, such as ChatGPT, Gemini, Bing, and so on. These can be useful tools in your work and there are some homework questions in which we ask you explicitly to use them. However, the use of such tools when it is not explicitly allowed will be treated as plagiarism and is strictly prohibited.
Data Mining, 2024
Data Mining
Academic year 2024–2025
"The success of companies like Google, Facebook, Amazon, and Netflix, not to mention Wall Street firms and industries from manufacturing and retail to healthcare, is increasingly driven by better tools for extracting meaning from very large quantities of data. 'Data Scientist' is now the hottest job title in Silicon Valley." – Tim O'Reilly
- Data Scientist: The Sexiest Job of the 21st Century
- Find true love with data mining
The course will develop algorithms and statistical techniques for data analysis and mining, with emphasis on massive data sets such as large network data. It will cover the main theoretical and practical aspects behind data mining.
The goal of the course is twofold. First, it will present the main theory behind the analysis of data. Second, it will be hands-on and at the end students will become familiar with various state-of-the-art tools and techniques for analyzing data.
We will use Python for downloading data and implementing various algorithms using its rich libraries and frameworks such as Spark, Storm, Giraph, and TensorFlow for mining of large-scale data.
Prerequisites
Students who wish to take this course should be familiar with Python programming.
Announcements
The fourth homework is out. It is due on December 29.
The third homework is out. It is due on December 1.
The second homework is out. It is due on November 17.
The first homework is out. It is due on November 3.
Make sure to register in the class mailing list. Email Aris to do so.
The first day of class is September 30.
Instructor
Aris Anagnostopoulos, Sapienza University of Rome.
Teaching Assistant (TA)
This email address is being protected from spambots. You need JavaScript enabled to view it. , Sapienza University of Rome.
When and where:
Monday 16.00–19.00, Room A5–A6
Wednesday 14.00–17.00, Room A5–A6
Office hours
You can use the office hours for any question regarding the class material, past or current homeworks, general questions on data mining, the meaning of life, pretty much anything. Send an email to Gianluca or, if needed, to Aris for arrangement.
Textbook and references
The main textbook is the "Mining of Massive Datasets," by J. Leskovec, A. Rajaraman, and J. D. Ullman. The printed version has been updated and you can download the latest version (currently 3) from the book's web site.
In addition, we will also use some chapters from some other textbooks, all available online:
- C. Aggarwal, "Data Mining: The Textbook," Springer (must be downloaded from Sapienza)
- M. J. Zaki and W. Meira, Jr., "Data Mining and Analysis: Fundamental Concepts and Algorithms," Cambridge University Press
- R. Zafarani, M. A. Abbasi, and H. Liu, "Social Media Mining: An Introduction," Cambridge University Press
- C. D. Manning, P. Raghavan, and H. Schütze, "Introduction to Information Retrieval," Cambridge University Press
- A. Blum, J. Hopcroft, and R. Kannan, "Foundations of Data Science," Cambridge University Press
The following book is not obligatory for the class, but is a vary useful book for the topic of feature engineering
- Pablo Duboue, "The Art of Feature Engineering," Cambridge University Press
For neural networks and GNNs, a nice book is
- Iddo Drori, "The Science of Deep Learning," Cambridge University Press
Finally, we will cover material from various sources, which we will post online as the course proceeds.
Python resources
The main programming language that we will use in the course is Python 3.
To learn the language you can find a lot of material online. You can start from Python's documentation site: https://www.python.org/doc/.
We will use several libraries in the class. The Anaconda distribution has packaged all of them together and you can download it for free.
If you have problems with Python installation you can obtain an ubuntu virtual machine with Python preinstalled. Contact Gianluca for more information.
Examination format
The evaluation will consist of two parts:
- 4 sets of homeworks
- A final project. Details will be given during the course
Late policy: Every homework must be returned by the due date. Homeworks that are late will lose 10% of the grade if they are up to 1 day (24h) late, 20% if they are 2 days late, 30% if they are 3 days late, and they will receive no credit if they are late for more than 3 days. However, you have a bonus of 3 late days, which you can distribute as you wish among all the homeworks. The homeworks will be discussed and graded at the end, during the final exam.
In addition, we will take into account participation during class.
Syllabus
Chapters for which no book is mentioned refer to the "Mining of Massive Datasets" (see above). For the other textbooks, we refer to with the author initials: A, ZM, ZAL, MRS, BHK.
| Date | Topic | Reading |
| September 30 | Introduction to data mining and data types, a crash course in probability | LRU Chapters 1.1, 1.3 Introduction to data mining, A crash course on discrete probability Check the background probability chapters below |
| October 2 | A crash course in probability (cont.) | |
| October 7 | Drash course in probability (cont.), similarity and distance measures |
Book chapter on quicksort
from the book of Mitzenmacher and Upfal on Probability and Computing Chapter 3.5 |
| October 14 | Preprocessing for text mining, the vector-space model, TF-IDF scoring, Inverted indexes | MRS Chapters 1.0–1.4, 2.0–2.2, 6.2, 7.1.0 |
| October 16 | Brief recap of Hadoop, MapReduce, and Spark; construction of large indexes. | LRU Chapters 3.4, 2.0–2.4, Quick introduction to MapReduce |
| October 21 | Lab on Apache SPARK | PySpark tutorial and slides by Fanilo Andrianasolo |
| October 23 | Shingles, minwise hashing | LRU Chapters 3.0–3.3 |
| October 28 | LSH, Introduction to clustering, hierarchical clustering | Chapters 3.4, 7.0–7.1.2, 7.2. | October 30 | k-means | Chapters 7.3.0–7.3.2. Chapter on k-means of the book of Christopher M. Bishop |
| November 4 | k-means++ | Paper by D. Arthur and S. Vassilvitskii | November 6 | Introduction to generative models, soft clustering, and expectation–maximization | Notes | November 11 | Principal component analysis, part 1 | Notes | November 13 | Principal component analysis, part 2 | Notes | November 18 | Principal component analysis, part 3 | Notes | November 20 | Some info on feature engineering |
| November 25 | Embeddings and Word2Vec | Original paper on Word2Vec |
| November 27 | PageRank and Personalized PageRank | LRU Chapters 5.1, 5.3 |
| December 2 | Node embeddings | Papers on DeepWalk and node2vec |
| December 4 | Graph neural networks, recommender systems | Book chapter on GNNs from the book of Drori The Science of Deep Learning, Slides |
on recommender systems
| December 9 | Explainability | |
| December 11 | Data Mining in Bioinformatics | |
| December 16 | Lab on GNNs and Explainability | |
| December 18 | Team formation |
Homeworks
Check the "Examination format" section below for information about collaborating, being late, and so on.
Handing in: You must hand in the homeworks by the due date and time by an email to the TA that will contain as attachment (not links!) a .zip or .tar.gz file with all your answers and subject
[Data Mining class] Homework #
where # is the homework number. After you submit, you will receive an acknowledgement email that your homework has been received and at what date and time. If you have not received an acknowledgement email within 2 days after the deadline then contact Gianluca.
The solutions for the theoretical exercises must contain your answers either typed up or hand written clearly and scanned.
The solutions for the programming assignments must contain the source code, instructions to run it, and the output generated (to the screen or to files).
We will not post the solutions
online, but we will present them in class.
- Homework 1 (due: 3/11/2024, 23.59)
- Homework 2 (due: 17/11/2024, 23.59)
- Homework 3 (due: 1/12/2024, 23.59)
- Homework 4 (due: 29/12/2024, 23.59)
Notes, slides, and other material
Book chapters and notes:
Background reading on combinatorics, basic probability, random variables, and basic probability distributions.
Collaboration policy (read
carefully!): You can discuss with other students of the course
about the projects. However, you must understand well your solutions and
the final writeup must be yours and written in isolation. In addition,
even though you may discuss about how you could implement an algorithm,
what type of libraries to use, and so on, the final code must be yours.
You may also consult the internet for information, as long as it does
not reveal the solution. If a question asks you to design and implement
an algorithm for a problem, it's fine if you find information about how
to resolve a problem with character encoding, for example, but it is not
fine if you search for the code or the algorithm for the problem you are
being asked. For the projects, you can talk with other students of the
course about questions on the programming language, libraries, some API
issue, and so on, but both the solutions and the programming must be
yours.
If we find out that you have violated the policy and you have
copied in any way you will automatically fail. If you have any
doubts about whether something is allowed or not, ask the
instructor.
The same applies for generative AI tools, such
as ChatGPT. These can be useful tools in your work and there
are some homework questions in which we ask you explicitly to use them.
However, the use of such tools when it is not explicitly allowed
will be treated as plagiarism and is strictly prohibited.
Algorithmic Methods of Data Mining (Sc.M. in Data Science), 2025
Algorithmic Methods of Data Mining (Sc.M. in Data Science)
Academic year 2025–2026
"The success of companies like Google, Facebook, Amazon, and Netflix, not to mention Wall Street firms and industries from manufacturing and retail to healthcare, is increasingly driven by better tools for extracting meaning from very large quantities of data. 'Data Scientist' is now the hottest job title in Silicon Valley." – Tim O'Reilly
The course will develop the basic algorithmic techniques for data analysis and mining, with emphasis on massive data sets such as large network data. It will cover the main theoretical and practical aspects behind data mining.
The goal of the course is twofold. First, it will present the main theory behind the analysis of data. Second, it will be hands-on and at the end students will become familiar with various state-of-the-art tools and techniques for analyzing data.
We will cover some very basic topics necessary for handling large data, such as hashing, sorting, graphs, data structures, and databases. We will then move to more advanced data mining topics: text mining, clustering, classification, mining of frequent itemsets, graph mining, visualization.
The theoretical part will be complemented by a laboratory where students will learn how to use tools for analyzing and mining large data.
Announcements
Given the general strike in Italy on Monday, we will start lectures on Tuesday, September 23.
The first day of the ADM classes is on September 22, 2025.
You need to register to:
- The class mailing list.
- Google classroom.
Instructors
Aris Anagnostopoulos, Sapienza University of Rome.
Luca Becchetti, Sapienza University of Rome.
Teaching Assistants (TA)
The best way to ask any questions is through Google classroom.
Loris Cino (This email address is being protected from spambots. You need JavaScript enabled to view it. ), Ph.D. candidate in Data Science, Sapienza University of Rome (LinkedIn).
When and where:
Monday 14.00–16.00, Via di Castro Laurenziano 7a (Building RM018), Room 2.
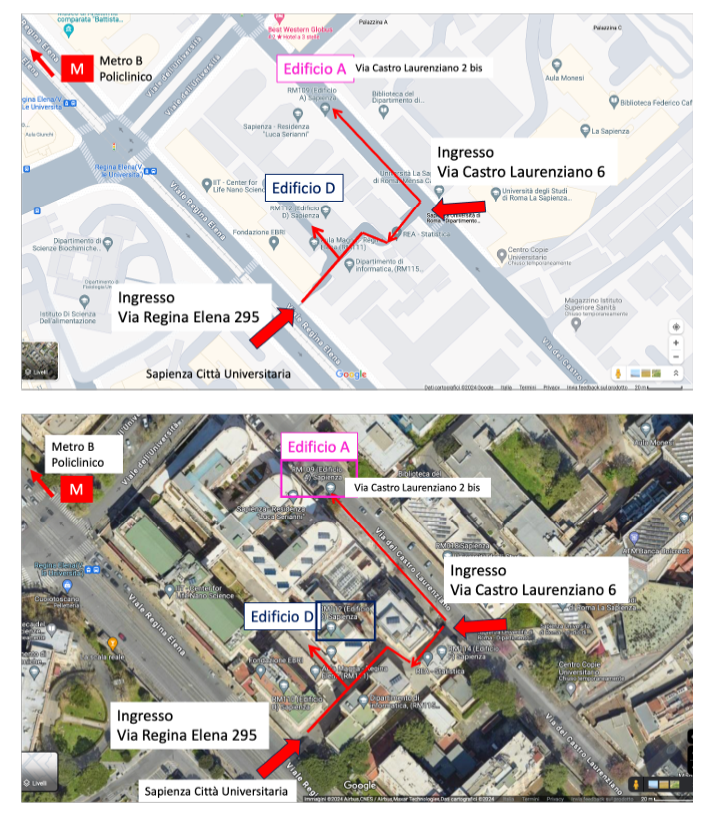
Thursday 14.00–16.00, Viale Regina Elena 295, Building D (RM112), Room 101.
{kind=link}
Lab: Tuesday 15.00–19.00, Via Tiburtina 205, Room 17.
Online lectures and nonattending students
There will not be lectures online, only in class. Attending the classes and the lab is, of course, highly recommended. In addition, participation (through making and answering questions) can increase your final grade.
We know that there are students who cannot be in Rome (workers, visa problems, etc.). We mainly use the blackboard during class and online attendance or registration would create overhead for the in-class students, sorry. Make sure that you follow the reading material provided during the semester in this web page.
Office hours
You can use the office hours for any question regarding the class material, past or current homeworks, general questions on data mining, the meaning of life, pretty much anything. The best resource is Google classroom. If this is not enough, you can send an email to the TAs and, if needed, to the instructors for arrangement.
Textbook and references
We will use a variety of textbooks. Whenever we can, we will try to find books that are available online. As the course progresses, we will indicate what you should read. The main books that we will use are the:
- (A) C. Aggarwal, "Data Mining: The Textbook," Springer (must be downloaded from Sapienza)
- (ZAL) R. Zafarani, M. A. Abbasi, and H. Liu, "Social Media Mining: An Introduction," Cambridge University Press
- (LRU) J. Leskovec, A. Rajaraman, and J. Ullman, "Mining of Massive Datasets," Cambridge University Press
- (MRS) C. D. Manning, P. Raghavan and H. Schütze, "Introduction to Information Retrieval," Cambridge University Press
- (J) J. Janssens, "Data Science at the Command Line", O'Reilly
In addition, we will cover material from various other sources, which we will post online as the course proceeds.
If you are interested in the topic of algorithms, we recommend the following books:
- T. Cormen, C. Leiserson, R. Rivest, and S. Stein, "Introduction to Algorithms" (4th ed): This is a classic book, very detailed, sometimes too verbose
- S. Dasgupta, C. Papadimitriou, and U. Vazirani, "Algorithms": Very succinct but well written, probably the first book to check out. If you cannot follow it, try one of the other books first
- T. Roughgarden, "Algorithms Illuminated": Another introductory text. It is a more recent book. Tim writes very well.
- J. Kleinberg, and E. Tardos, "Algorithm Design": This is a more advanced book, probably not recommended if it is your first contact with algorithms, but will increase your knowledge a lot if you already know the basic concepts.
Python resources
The main programming language that we will use in the course is Python 3.
To learn the language you can find a lot of material online. You can start from Python's documentation site: https://www.python.org/doc/.
If you would like to buy some books, you can check the
- "Learning Python, 6th edition," by Mark Lutz. It is a bit verbose, but it presents well the features of the language.
- "Python Pocket Reference, 5th edition," by Mark Lutz. It is usefull as a quick reference if you know more or less the language and you are searching for some information.
We will use several libraries in the class. For Windows users the Anaconda distribution has packaged all of them together and you can download it for free. For MAC/Linux users, all packages can be installed using the pip3 tool.
We will also use Python (Jupyter) notebooks. You can find instructions for the installation at the Jupyter web site.
If you have problems with Python installation you can obtain an ubuntu virtual machine with Python preinstalled. Contact the instructor for more information.
Examination format
There are two ways to pass the class:
One is:- Do a take-home homework.
- Do a hackathon that we will set up at the end of the semester.
- Do a 1-hour written exam, where we will ask you basic concepts that we have covered during the semester.
- Do a 2-hour more extended written exam.
In addition, we will take into account participation during class.
Syllabus and lecture material
Make sure that you register to the class mailing list and to Google classroom to be able to get this information. See the Announcements above.
Social Networks and Online Markets, 2025
Social Networks and Online Markets
Academic year 2024–2025
We are surrounded by networks. The Internet, one of the most advanced artifacts ever created by mankind, is the paradigmatic example of a "network of networks" with unprecedented technological, economical and social ramifications. Online social networks have become a major driving phenomenon on the web since the Internet has expanded as to include users and their social systems in its description and operation. Technological networks such as the cellular phone network or the energy grid support many aspects of our daily life. Moreover, there is a growing number of highly-popular user-centric applications in Internet that rely on social networks for mining and filtering information, for providing recommendations, as well as for ranking of documents and services.
In this course we will present the design principles and the main structural properties and theoretical models of online social networks and technological networks, algorithms for data mining in social networks, and the basic network economic issues, with an eye towards the current research issues in the area.
Announcements
Remember to register your email; email Aris for details.
Classes start on Wednesday, February 26.
Topics that we will cover
- Properties of social networks
- Models for social networks
- Community detection
- Spectral techniques for community detection
- Cascading behavior in social networks and epidemics
- Influence maximization and viral marketing
- Influence and homophily
- Opinion dynamics
- Machine learning on graphs
- Introduction to Game Theory and Computational issues
- Price of Anarchy and Selfish Routing
- Stable matching, Markets, Competitive equilibria
- Sponsored Search Auctions, VCG, Revenue Maximization
- Voting and Fair division
- Equilibria and Incentives in blockchains and cryptocurrencies
Instructors
Aris Anagnostopoulos, Sapienza University of Rome
Stefano Leonardi, Sapienza University of Rome
When and where:
Monday 15.00–17.00, Via Ariosto 25, Room A5
Wednesday 12.00–15.00, Via Ariosto 25, Room A7
Office hours
You can use the office hours for any question regarding the class material, general questions on networks, the meaning of life, pretty much anything. Send an email to the instructors for arrangement.
Textbook and references
The main textbook for the first part is the book Networks, Crowds, and Markets: Reasoning About a Highly Connected World, by David Easley and Jon Kleinberg.
The main textbook for the second part is the book Twenty Lectures on Algorithmic Game Theory, by Tim Roughgarden.
In addition, we will cover material from various other sources, which we will post online as the course proceeds.
Evaluation format
You will be evaluated for the two parts of the course (social networks, online markets) independently from each other, and your grade will be the average of the two parts.
For the part of social networks, it will be discussed in class. Usually, there is (1) an individual homework (deadline in the first week of June), (2) a small project that can be done in groups of at most two people (deadline 4 working days before the date that you try the oral exam), and (3) a light oral exam.
For the part of online markets, Stefano Leonardi will provide more details.
Alternatively, there is also the option of a written exam for both parts.
Syllabus
Unless otherwise specified, the chapter numbers refer to the book of Easley and Kleinberg mentioned above.| Date | Topic | Reading |
| February 26 | Introduction to social networks and online markets, Properties of complex networks. | |
| March 3 | Tie strength, homophily, triadic closure, affiliation networks |
|
| March 5 | Modeling phenomena and social networks, the Erdős–Rényi random-graph model, the Watts–Strogatz small-world model |
|
| March 10 | The preferential attachment model |
|
| March 12 | Epidemics and Influcence, Models of influence | |
| March 17 | Influcence maximization in social networks | |
| March 19 | Social influence vs. social correlation, the densest subgraph problem |
|
| March 24 | The densest subgraph problem (cont.), community detection and sparsest cut | |
| March 26 | Community detection and sparsest cut (cont.) |
|
| March 31 | Spectral clustering |
|
| April 9 | Nonlinear embeddings, random walks, graph neural networks |
|
Homeworks
- Homework 1 (due: 8/6/2025, 23.59)
Collaboration policy (read
carefully!): You can discuss with other students of the course
about the projects. However, you must understand well your solutions and
the final writeup must be yours and written in isolation. In addition,
even though you may discuss about how you could implement an algorithm,
what type of libraries to use, and so on, the final code must be yours.
You may also consult the internet for information, as long as it does
not reveal the solution. If a question asks you to design and implement
an algorithm for a problem, it's fine if you find information about how
to resolve a problem with character encoding, for example, but it is not
fine if you search for the code or the algorithm for the problem you are
being asked. For the projects, you can talk with other students of the
course about questions on the programming language, libraries, some API
issue, and so on, but both the solutions and the programming must be
yours.
If we find out that you have violated the policy and you have
copied in any way you will automatically fail. If you have any
doubts about whether something is allowed or not, ask the
instructor.
The same applies for generative AI tools, such
as ChatGPT. These can be useful tools in your work and there
are some homework questions in which we ask you explicitly to use them.
However, the use of such tools when it is not explicitly allowed
will be treated as plagiarism and is strictly prohibited.
Data Mining, 2025
Data Mining
Academic year 2025–2026
"The success of companies like Google, Facebook, Amazon, and Netflix, not to mention Wall Street firms and industries from manufacturing and retail to healthcare, is increasingly driven by better tools for extracting meaning from very large quantities of data. 'Data Scientist' is now the hottest job title in Silicon Valley." – Tim O'Reilly
The course will develop algorithms and statistical techniques for data analysis and mining, with emphasis on massive data sets such. It will cover the main aspects behind data mining.
Announcements
There is no class on September 22, given that 2nd-year courses start on the 24th. First class will be on September 25.
The first day of class is September 22; it will start a bit late, at 16.30.
You need to register to:
- The class mailing list.
- Google classroom.
Instructors
Aris Anagnostopoulos, Sapienza University of Rome.
Luca Becchetti, Sapienza University of Rome.
When and where:
Monday 16.00–19.00, Room A5–A6
Thursday 12.00–14.00, Room A5–A6
Office hours
You can use the office hours for any question regarding the class material, past or current homeworks, general questions on data mining, the meaning of life, pretty much anything. The best resource is Google classroom. If this is not enough, you can send an email to the TAs and, if needed, to the instructors for arrangement.
Textbook and references
The main textbook is the "Mining of Massive Datasets," by J. Leskovec, A. Rajaraman, and J. D. Ullman. The printed version has been updated and you can download the latest version (currently 3) from the book's web site.
In addition, we will also use some chapters from some other textbooks, all available online:
- C. Aggarwal, "Data Mining: The Textbook," Springer (must be downloaded from Sapienza)
- M. J. Zaki and W. Meira, Jr., "Data Mining and Analysis: Fundamental Concepts and Algorithms," Cambridge University Press
- R. Zafarani, M. A. Abbasi, and H. Liu, "Social Media Mining: An Introduction," Cambridge University Press
- C. D. Manning, P. Raghavan, and H. Schütze, "Introduction to Information Retrieval," Cambridge University Press
- A. Blum, J. Hopcroft, and R. Kannan, "Foundations of Data Science," Cambridge University Press
The following book is not obligatory for the class, but is a vary useful book for the topic of feature engineering
- Pablo Duboue, "The Art of Feature Engineering," Cambridge University Press
Finally, we will cover material from various sources, which we will post online as the course proceeds.
Examination format
There are two ways to pass the class:
One is:- Do a hackathon that we will set up at the end of the semester.
- Do a 1-hour written exam, where we will ask you basic concepts that we have covered during the semester.
- Do a 2-hour more extended written exam.
In addition, we will take into account participation during class.
Syllabus and lecture material
Make sure that you register to the class mailing list and to Google classroom to be able to get this information. See the Announcements above.